CoProcessor Components
Different components of coprocessor and how they interact with each other
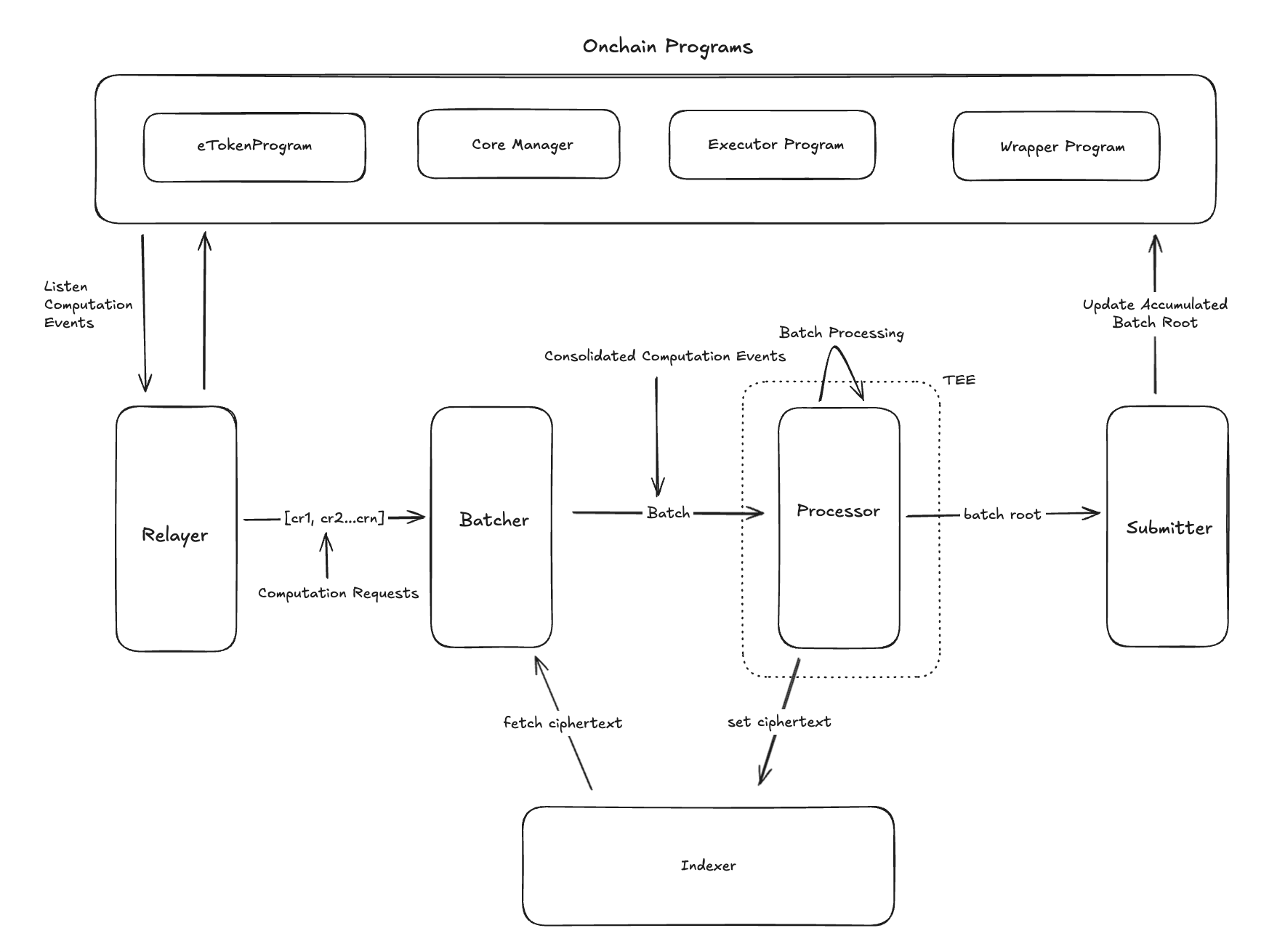
There are several components which works in conjunction to enable computation on encrypted data within Encifher CoProcessor.
Processor
The processor component processes off-chain batch data (generated by batcher component) within trusted execution environment (TEE). It decrypts and computes data through a specialized client, producing verifiable outputs like signed hashes and Merkle roots. Supporting various computation flows, it offers a set of API endpoints for batch processing, re-encryption, and timestamp retrieval. Underlying operations are backed by local databases that manage state and enforce access control. While computation it calculates the same resultant handle which are calculated onchain as a result of symbolic execution and assign ciphertext against those handles.
Indexer
The indexer stores and serves handle→ciphertext mappings with verification data (data required to verify retreival of valid ciphertext) in sled db records keyed by the handle (as string). Its HTTP interfaces are POST /v1/set-batch-tree to calculated batch tree, POST /v1/set-ciphertext to store a single handle ciphertext mapping, and POST /v1/get-ciphertext / POST /v1/get-ciphertexts to retrieve a single or a list of ciphertexts. The Indexer derives inclusion proofs from provided leaf hashes when inserting a batch.
Relayer
A relayer listens to on‑chain program events, decodes pointer operations, and enqueues those computation request into a Kafka queue which is consumed by Batcher for generated BatchData structs.
Batcher
The batcher groups related operations by handle overlap and time window, fetches required ciphertexts from the Indexer, and produces BatchData for the Processor. It deduplicates handles and builds dependency groups so operations that depend on previous results are ordered correctly.
Submitter
The submitter commits batch roots onchain through core manager program for verification while storing full batch data offchain. It receives accumulator root, TEE signature, recovery ID, and batch tree data from processor. Batch trees are serialized to JSON, compressed using zlib default compression, and base64 encoded before submission. Data availability layer uses Turbo DA client with API key authentication, submitting compressed batches and receiving submission IDs for onchain reference. Blockchain submission loads Solana configuration including RPC URL, submitter keypair path, cluster setting, and core manager program ID. Chain client builds updateBatchRoot instruction with signature, recovery ID, accumulator root, and DA submission ID reference. Retry logic uses exponential backoff for transient failures while maintaining submission status tracking. Environment variable AVAIL_DA_MOCK enables testing mode that skips actual DA submission and generates mock submission IDs. Submission flow compresses batch data first, uploads to Turbo DA, waits for submission confirmation, then submits cryptographic proof with DA reference to blockchain for verification.
Trusted Execution Environment
The trusted execution environment isolates decrypt and compute operations with verifiable signing and (in deployment) attestation binding code identity to a public key. In this codebase, TEE usage is limited to producing signatures for batch hashes and merkle roots (tee_sign) and reading a public key from environment; full enclave deployment/attestation is configured externally. One deployment option uses Marlin Oyster on AWS Nitro Enclaves, where a custom networking stack enables standard web applications within the TEE. Oyster CVM mode provides dedicated enclave instances with init‑params to inject configuration and secrets. During enclave boot, files are mounted at /init-params for applications to read (for example, processor config). The enclave lifecycle covers image provisioning, init‑params injection, attestation, and teardown.
In Marlin Oyster deployments, key management may use Marlin Nautilus for deterministic secp256k1 derivation via an in‑enclave derive server, with epoch‑based rotation (for example, app/encipher-v1/epoch-YYYY-wNN). Attestation can produce AWS Nitro attestation documents with PCR measurements for code, init params, and environment; a verifier can check these measurements against expected image IDs and bind a public key to the enclave identity. These deployment details are optional and not implemented directly in this repository; see official deployment docs for the end‑to‑end attestation and key management flow.
More about Marlin here: https://docs.marlin.org/oyster/introduction-to-marlin/trusted-execution-environments